
DeepSeek-R1推理腹地跑,7GB GPU体验啊哈时刻?GitHub超2万星
剪辑:KingHZ Aeneas
【新智元导读】黑科技来了!开源LLM微调神器Unsloth近期更新,将GRPO历练的内存使用减少了80%!只需7GB VRAM,腹地就能体验AI「啊哈时刻」。
李飞飞团队仅用16张H100训了26分钟,训出的模子就杰出了o1-preview,摇荡业内。
不错说,DeepSeek-R1依然让环球AI模子走向了推理新期间。
甚而期骗其历练重要GRPO,AI开源界动手了竞赛:看谁能用最少的资本,复现AI的「啊哈时刻」。
而就在刚刚,DeepSeek-R1的推理资本澈底被打下来了!
开源边幅Unsloth AI带来了好音尘,无谓云作事,腹地也能体验「Aha」 时刻:
当今不错在腹地建立上复现DeepSeek-R1的推理!
只需7GB VRAM,你就能体验到「Aha」时刻。
Unsloth把GRPO历练需要的内存减少了80%。
15GB VRAM就不错把Llama-3.1(8B)和Phi-4(14B)改换为推理模子。

莫得看错:只需7GB VRAM的GPU,AI模子在腹地就能体验「啊哈时刻」。
什么是AI的「啊哈时刻」?有什么作用?
老练AI的皆知谈,对东谈主类很简短的问题,对AI可能很难。比如:
9.11和9.9比拟,哪个大?
但体验过「Aha」时刻后,AI模子Phi-4就能完成这类问题:从无推理能力的模子,化身为DeepSeek-R1同款推理模式,带有原始念念维链、展示推理过程的那种!

原文麇集:https://unsloth.ai/blog/r1-reasoning
总之,要是当今你依然有输入和输出数据(比如问题和谜底),但莫得CoT或推理过程,那就不错见证GRPO创造的名胜了——
它能为你创建推理过程,甚而作念出更多!
当今,这个重要依然在AI社区爆火,盘考的声浪越来越高了。
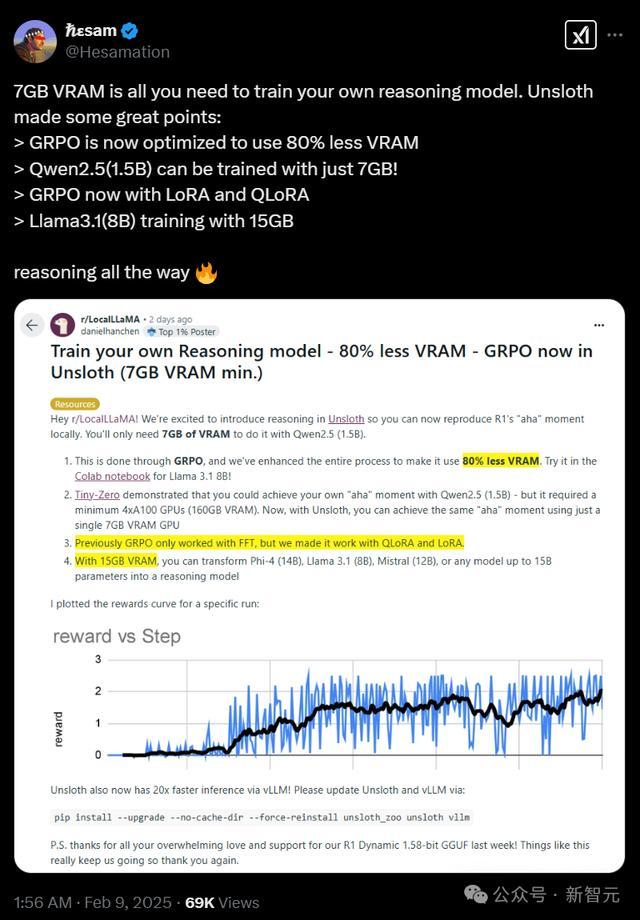
Unsloth推出推理功能
DeepSeek的R1磋商揭示了「Aha」时刻,通过群体相对战略优化(Group Relative Policy Optimization,GRPO),在莫得东谈主类反应的情况下,R1-Zero自动学会了如何分拨更多的念念考时期。
Unsloth对系数GRPO过程进行了增强,比拟Hugging Face+FA2,VRAM使用减少了80%。
这意味着只需7GB VRAM,使用Qwen2.5(1.5B)就能重现R1-Zero的「Aha」时刻。

边幅麇集:https://github.com/unslothai/unsloth
对于包含其他模子的GRPO,参阅下列文档。
文档麇集:https://docs.unsloth.ai/get-started/unsloth-notebooks
这次,unsloth更新主要增强了对DeepSeek-R1-Zero强化学习历练重要的GRPO撑抓,减少了对内存的占用。
主要亮点如下:
15GB VRAM:使用unsloth,你不错将任何最多15B参数的模子(如Llama 3.1(8B)、Phi-4(14B)、Mistral(7B)或Qwen2.5(7B))补助为推理模子。
最低仅需7GB VRAM,足以在腹地历练你我方的推理模子。
Tiny-Zero团队曾展示过,使用Qwen2.5(1.5B)不错竣事「aha」时刻,但需要2个A100 GPU(160GB VRAM)。而当今,借助Unsloth,只需一个7GB VRAM的GPU就能竣事调换的成果。
之前,GRPO仅撑抓无缺微调,但当今依然概况与QLoRA和LoRA合作使用。
请阻扰,这并不是微调DeepSeek-R1蒸馏模子或用R1蒸馏数据进行调优(Unsloth依然撑抓)。内容上,此边幅用GRPO将圭臬模子摇荡为「满血」的推理模子。
GRPO的应用场景:带有奖励机制的定制化推理模子,例如法律、医学等界限;其他需要表露推理链或念念维过程的场景。
GRPO带来的「Aha」时刻
在使用纯正的强化学习(RL)历练R1-Zero时,DeepSeek不雅察到了神奇的「啊哈时刻」——
在莫得任何东谈主类的指挥或预界说的指示的情况下,模子竟动手重新评估其启动重要,学会了蔓延念念考时期。
即便只使用GRPO对Phi-4作念100步的历练,限制也一目了然:未使用GRPO的模子莫得念念考token,使用GRPO历练后的模子则具有念念考token,而且得出了正确谜底!

论文麇集:https://arxiv.org/pdf/2412.08905
这种「啊哈时刻」标明,GRPO不仅匡助模子莳植推理能力,还能让模子在莫得外部指示的情况下,学会自我反念念和补助,从而提高问题责罚的质料。
回到「9.11和9.9哪个大?」的问题,莫得GRPO历练前,Phi-4先容了如何从左到右按位比较少量,坚抓觉得天然十分位上1<9,但百分位上1>0,而9.9不错写稿9.90, 是以:「9.11比9.90大」。
经过GRPO历练,Phi-4依然能正确分析酬劳此问题了,而且推理过程明晰,严丝合缝——
在推理过程中的第2步,基于十分位的比较,依然得出了正确谜底;在第3步,依然比较了9.11和9.90的百分位,但这次AI模子发现比较百分位并不影响在第2步得出的限制。

Phi-4在GRPO历练前后比较,指示为:「Which is bigger? 9.11 or 9.9?」
这便是GRPO的「魅力」。
GRPO是一种强化学习(RL)算法,与近端战略优化(Proximal Policy Optimization,PPO)不同,它不依赖值函数,概况更高效地优化模子的酬劳质料。
在项想法Notebook中,使用GRPO历练模子,概况自主发展出自我考证(self-verification)和搜索能力,从而创造出一个迷你「Aha 时刻」。
GRPO的大致历程如下:
1 模子生成多组酬劳
2 说明正确性或其他设定的奖励函数,炒汇对酬劳进行评分(不同于使用LLM手脚奖励模子)
3 操办该组酬劳的平均得分
4 将每个酬劳的得分与组内平均得分进行比较
5 增强模子对高分酬劳的偏好
例如来说,假定要模子责罚下列问题:
What is 1+1? >> Chain of thought/working out >> The answer is 2.
What is 2+2? >> Chain of thought/working out >> The answer is 4.
来源,必须收罗无数数据来填充责任/念念维链。
关联词,GRPO(DeepSeek使用的算法)以过甚他RL算法不错指挥模子自动走漏出推理能力,并创建推理轨迹。
RL不需要数据,违反需要悉心操办的奖励函数或考证器。例如,要是它得到了正确谜底,就给它打1分;要是有些单词拼写无理,就减0.1分。依此类推。
强强搭伙:在Unsloth中使用GRPO
要是在腹地使用GRPO进行历练,请先安设必要的依赖项:pip install diffusers。

历练指示:耐性恭候至少300步才能看到奖励分数的较着莳植;为了确保最好兼容性,请使用最新版块的vLLM。
Colab示例仅历练了1小时,限制较一般,要取得高质料限制,提议历练至少12小时(但不错随时罢手)。
较小的模子可能无法生成念念考token,提议至少使用1.5B参数的模子,正确生成「念念考token」(thinking tokens)。
要是使用基础模子,请确保加载正确的Chat模板(幸免体式问题)。
Unsloth现已内置GRPO历练亏空追踪功能,无需再使用外部器具(如wandb)。
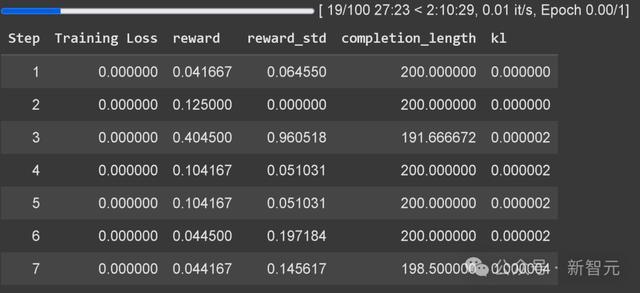
内置GRPO历练亏空追踪示例
更多强化学习历练重要
除了新增GRPO撑抓,还增多了对Online DPO(在线平直偏好优化)、PPO(近端战略优化)和RLOO(强化学习偏好优化)的撑抓!
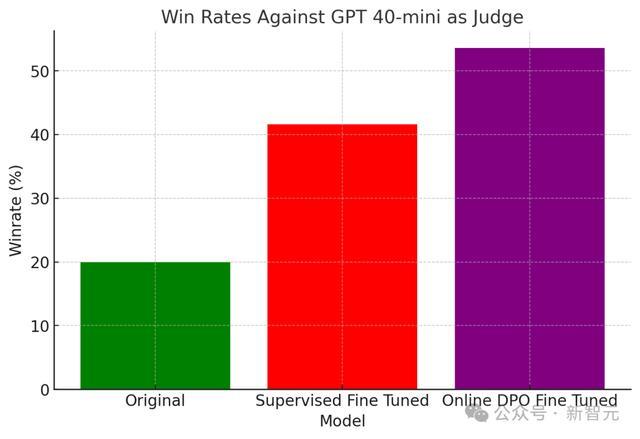
操办机工程专科的硕士生Keith Truongcao,在Unsolth中竣事了Online DPO算法。
在TLDR数据集 ,他使用GPT 4o-mini手脚判断模子,与原始模子(下图用绿色示意)比拟,微调后的AI模子胜率皆有所莳植:Online DPO模子(下图用紫色示意)的胜率显耀高于原始模子,况且比SFT模子(下图用红色示意)跨越12%,充领会释了强化学习历练重要的有用性。
借助Unsloth的优化,在线DPO(Direct Preference Optimization微调的显存需求大幅裁减。当batch size为1且使用梯度蕴蓄时,所需显存仅为20GB。
比拟之下,圭臬的Llama 3.2(10亿参数模子) 需要50GB显存,但在尝试非凡分拨2GB显存时,会发生OOM(内存溢出)无理。更令东谈主骇怪的是,即使在配备48GB显存的A40 GPU上,圭臬Llama也会平直崩溃。

Unsloth的在线DPO VRAM奢靡与Hugging Face+FA2的对比
更多细目,请参阅Keith的下列著作,其中包括如何让在线DPO平日责任更多细节。

原文麇集:https://substack.com/home/post/p-154490380
另一位活跃的开源孝顺者Joey,在X上也详确先容了我方如安在Google Colab上竣事GRPO变更的重要。
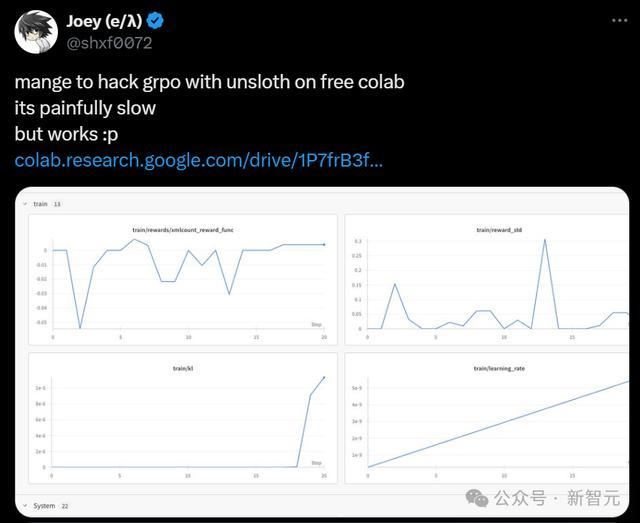
Unsloth x vLLM:更高糊涂量和更少VRAM奢靡
20倍糊涂量,一半VRAM
当今,在微调历程中,不错平直使用vLLM,这使得模子的糊涂量大幅莳植,况且不错同期进行微长入推理。

在1x A100 40GB GPU上,使用Unsloth动态4bit量化的Llama 3.2 3B Instruct,糊涂量约莫为4000 tokens/s。
在16GB Tesla T4(免费Colab GPU)上,糊涂量约莫为300 tokens/s。
而且,因为Unsloth还神奇地去除了vLLM和Unsloth沿途加载时的双重内存使用,因此让Llama 3.1 8B量入为主了约5GB VRAM,让Llama 3.2 3B量入为主了3GB VRAM。
加载模子时不再需要非凡的内存支拨。
Unsloth不错在单张48GB GPU上微调Llama 3.3 70B Instruct,其中Llama 3.3 70B的权重占用40GB VRAM。
这是Unsloth的原创功能。
而要是不优化内存经管,同期加载Unsloth和vLLM,会导致VRAM双倍占用,从而需要至少80GB VRAM才能运行。
而且上手相配快,只消两步:
安设vLLM和Unsloth:pip install unsloth vllm。
启动化Unsloth并启用快速推理:

Unsloth中对于vLLM的发现
1. 当今,vLLM不错加载Unsloth Dynamic 4-比特量化。就像Unsloth的1.58比特动态R1 GGUF同样,发现将某些层动态量化为4比特,将某些层动态量化为16比特,在减小模子限度的同期,显耀提高精准度。
2. 对于RAM、VRAM效率和最大糊涂量(如分块预填充标记数、最大序列数等)等建立,还不错自动选定多个参数。在vLLM中默许启用-O3并启用前缀缓存。发现老GPU上的Flashinfer内容上要慢10%。FP8 KV缓存会让速率慢10%,但糊涂量会翻倍。
3. 在vLLM中通过贯通情景字典,允许加载LoRA,而不是从磁盘加载——不错让GRPO历练运行速率提高1.5倍。在vLLM中平直剪辑LoRA适配器,干系磋商是否活跃。这不错大大提高速率,因为当前版块的算法还作念了不必要的GPU数据移动。
4. vLLM会诡外乡出现立时VRAM峰值,尤其是在批量生成时。为此在unsloth中,添加了批量生见效劳,以减少内存峰值。
Unsloth团队先容
另外值得一提的是,Unsloth当前在Github上有2万多星,但中枢团队Unsloth AI,只消两昆季。

Daniel Han,Unsloth AI的CTO,2021年毕业于悉尼科技大学。2022-2023年,在悉尼的MoonShot AI担任开源开辟者。

Michael Han,Unsloth AI的CEO,2019年毕业于新南威尔士大学(The University of New South Wales,UNSW)。在实习技术,他曾提高了多个算法竣事的速率。
下一篇:物理七巧板